on
Apache Hadoop HDFS Mimarisi
İçerik
- NameNode
- DataNode
- İkincil NameNode
- Bloklar
- Çoğaltma Yönetimi
- Raf Farkındalığı
- Raf Farkındalığı Avantajları
- HDFS Okuma / Yazma
- HDFS Okuma Mimarisi
HDFS (Hadoop Dağıtılmış Dosya Sistemi), her dosyanın önceden belirlenmiş bir bir boyuta bölünmüş blok yapılı bir dosya sistemidir. Bu bloklar bir veya bir kaç makinenin oluşturduğu kümelerde saklanır. Hadoop HDFS Mimarisinde, bir küme, tek bir NameNode (Ana Düğüm) ve diğer tüm düğümler DataNode (Slave düğümleri) içeren bir Master / Slave mimarisi izler.

NameNode (İsim Düğümü):
NameNode, DataNode’da bulunan blokları koruyon ve yöneten Apache Hadoop Mimarisinde bulunan ana düğümdür. NameNode, Dosya Sistemi İsim Alanını yöneten ve istemciler tarafından dosyalara erişimi denetleyen bir sunucudur. HDFS Mimarisi, kullanıcı verilerinin hiçbir zaman NameNode üzerinde bulunmayacağı şekilde oluşturulmuştur. Veriler yalnızca DataNode’larda bulunur. NameNode İşlevleri:
- DataNode’ları koruyan ve yöneten düğümdür.
- Kümede depolanan tüm dosyaların meta verilerini kaydeder. Örneğin saklanan blokların konumu, dosyaların boyutu, izinler, vb. Meta verilerle ilişkili iki dosya vardır:
- FsImage: NameNode başlangıcından bu yana dosya sistemi ad alanının tam durumunu içerir.
- EditLogs: Dosya sisteminde en yeni FsImage’e göre yapılan son değişiklikleri içerir.
- Dosya sistemi meta verilerinde gerçekleşen her değişikliği kaydeder. Örneğin, bir dosya HDFS’de silinirse NameNode bunu EditLog’a kaydeder.
- DataNode’ların canlı olduğundan emin olmak için kümedeki tüm DataNode’lardan düzenli olarak bir Heartbeat (Kalp atışı) ve bir blok raporu alır.
- HDFS’deki tüm blokların ve bu blokların hangi düğümlerde bulunduğunun kaydını tutar.
DataNode (Veri Düğümü):
DataNode’lar, HDFS’deki bağımlı düğümlerdir. DataNode, NameNode’un aksine, yüksek özellikli olmasına gerek olmayan bir sistemdir. DataNode, veriyi ext3 veya ext4 yerel dosyasına depolayan bir blok sunucudur.
- Her bağımlı makine üzerinde çalışan süreçlerdir.
- Gerçek veriler DataNode’da saklanır.
- DataNode’ları, dosya sistemi istemcilerinden gelen düşük seviye okuma ve yazma isteklerini gerçekleştirir.
- HDFS’nin genel sağlık durumunu bildirmek için periyodik olarak NameNode’a kalp atışı gönderirler, varsayılan olarak bu frekans değeri 3 saniyedir.
Secondary NameNode (İkincil İsim Düğümü)
Secondary NameNode yardımcı bir arka plan olarak birincil NameNode ile aynı anda çalışır. Secondary NameNode yedek bir NameNode değildir. İşlevleri:
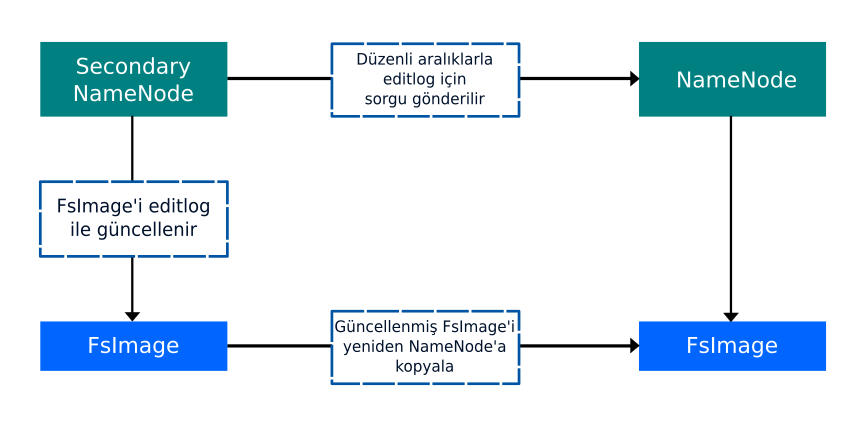
- Tüm dosya sistemlerini ve meta veriyi sürekli olarak NameNode’un RAM’inden okur ve sabit diske veya dosya sistemine yazar.
- NameNode’dan alınan EditLog’ları FsImage ile birleştirmekle sorumludur.
Bloklar:
Bloklar, verilerin saklandığı sabit diskinizdeki en küçük parçalardır. Genel olarak, herhangi bir dosya sisteminde, veriler bloklar koleksiyonu olarak saklanır. Benzer şekilde, HDFS, her dosyayı Apache Hadoop kümesinde dağınık bloklar olarak depolar. Apache Hadoop 2’de her bloğun varsayılan boyutu 128 MB’dir. Bu boyut değiştirilebilir.
 HDFS’de her dosyanın blok boyutunun tam katında (128 MB, 256 MB) depolanması gerekli değildir.
HDFS’de her dosyanın blok boyutunun tam katında (128 MB, 256 MB) depolanması gerekli değildir.
Replication Management (Çoğaltma Yönetimi):
HDFS, büyük verileri dağıtılmış bir ortama veri blokları halinde depolamanın güvenli bir yolunu sunar. Bu veri blokları aynı zamanda hata toleransı sağlamak için çoğaltılmaktadır. Varsayılan olarak çoğaltma sayısı 3’tür ve değiştirilebilir. Her bir bloğun 3 kez çoğaltıldığı ve farklı DataNode’larda depolandığı bir örnek aşağıdadır.
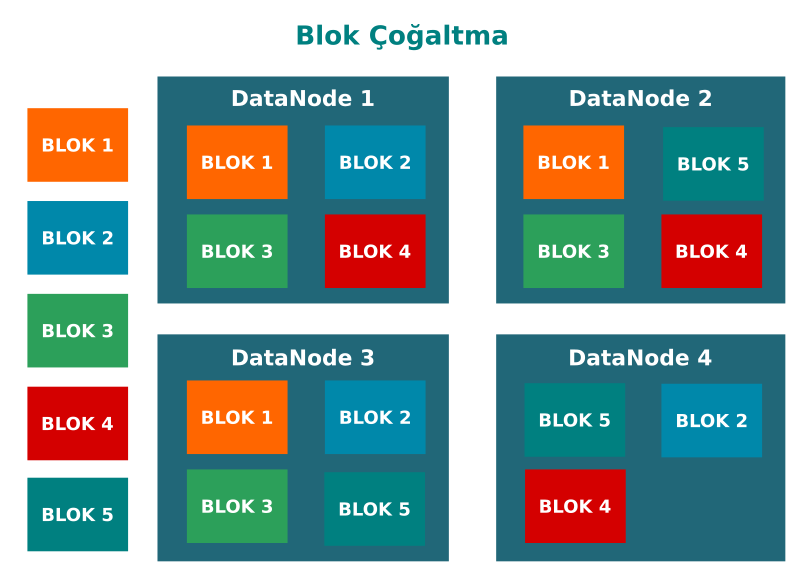 NameNode, çoğaltma faktörünü korumak için DataNode’dan periyodik olarak blok raporu toplar. Bu nedenle, fazladan veya eksik çoğaltma yapılırsa, NameNode blokları siler veya ekler.
NameNode, çoğaltma faktörünü korumak için DataNode’dan periyodik olarak blok raporu toplar. Bu nedenle, fazladan veya eksik çoğaltma yapılırsa, NameNode blokları siler veya ekler.
Rack Awareness (Raf Farkındalığı):
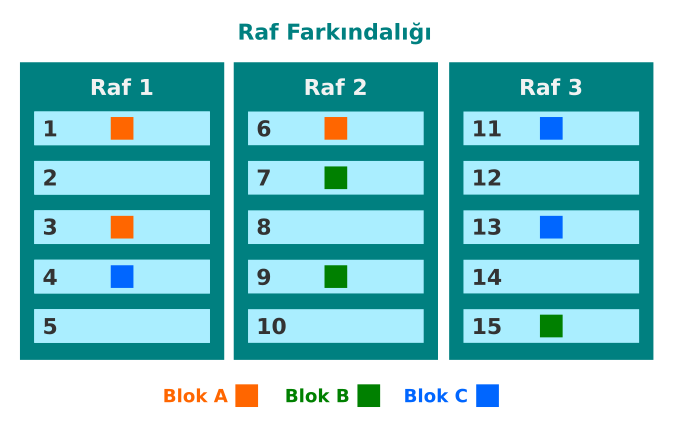 NameNode tüm kopyaların aynı rafta veya tek bir rafa depolanmamasını sağlar. Gecikmeyi azaltmanın yanı sıra hata toleransı sağlamak için yerleşik bir Rack Awereness Algoritması kullanır. Çoğaltma faktörü 3 olduğu düşünülürse, algoritma, bir bloğun ilk kopyasını yerel bir raf üzerinde depolar ve sonraki iki kopyayı farklı (uzak) bir rafa depolar. Aynı rafta ikiden fazla kopyanın bulunmaması koşuluyla, kopyaların geri kalanı rastgele DataNode’lara yerleştirilir.
Bir Hadoop kümesi örneği aşağıdadır. DataNode’lar ile doldurulan birden fazla raf bulunur.
NameNode tüm kopyaların aynı rafta veya tek bir rafa depolanmamasını sağlar. Gecikmeyi azaltmanın yanı sıra hata toleransı sağlamak için yerleşik bir Rack Awereness Algoritması kullanır. Çoğaltma faktörü 3 olduğu düşünülürse, algoritma, bir bloğun ilk kopyasını yerel bir raf üzerinde depolar ve sonraki iki kopyayı farklı (uzak) bir rafa depolar. Aynı rafta ikiden fazla kopyanın bulunmaması koşuluyla, kopyaların geri kalanı rastgele DataNode’lara yerleştirilir.
Bir Hadoop kümesi örneği aşağıdadır. DataNode’lar ile doldurulan birden fazla raf bulunur.
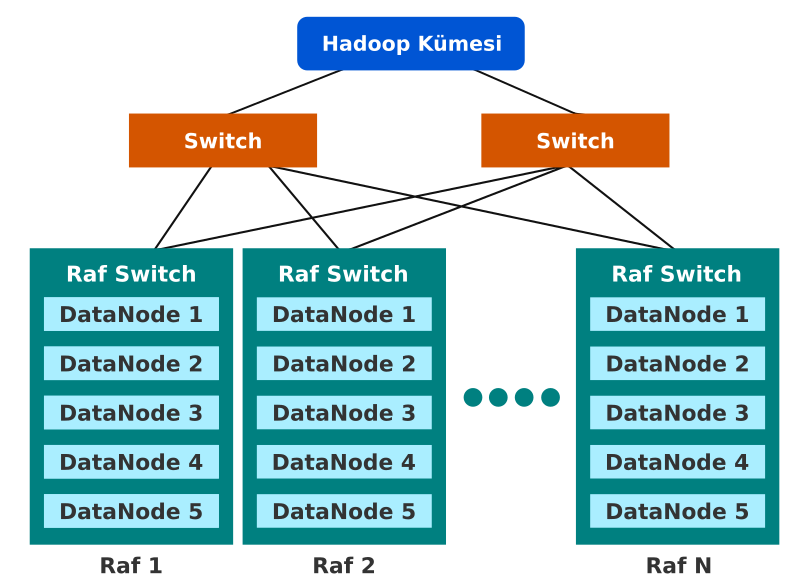
Raf Farkındalığı Avantajları:
- Ağ Performansını İyileştirmek:
Farklı raflarda bulunan düğümler arasındaki iletişim, switch (anahtar) aracılığıyla yönlendirilir. Genel olarak, farklı rafta bulunan makinelere kıyasla aynı raftaki makineler arasında daha fazla bant genişliği bulunur. Böylece, farklı raflar arasında yazma trafiğini azaltmanıza ve daha iyi bir yazma performansı elde etmenize yardımcı olur. Ayrıca, birden çok rafın bant genişliğini kullandığınız için artan bir okuma performansı elde edersiniz. - Veri Kaybını Önlemek:
Anahtar arızalanırsa veya elektrik kesintisi nedeniyle herhangi bir raf iptal olsa bile diğer raflarda blokların yedeği olduğu için herhangi bir sorun olmaz.
HDFS Okuma / Yazma
Bir HDFS istemcisinin 248 MB boyutundaki bir dosyayı yazmak istediğini varsayalım.
 Veriler HDFS’ye yazılmak istendiğinde aşağıdaki adımlar gerçekleşecek:
Veriler HDFS’ye yazılmak istendiğinde aşağıdaki adımlar gerçekleşecek:
- İlk önce, HDFS istemcisi iki blok için NameNode’a yazma isteği için ulaşır.
- NameNode istemciye yazma izni verir ve blokların kopyalanacağı DataNode’ların IP adreslerini sağlar.
- DataNode’ları seçimi, daha önce de incelediğimiz gibi, erişilebilirlik, çoğaltma faktörü ve raf farkındalığı temelinde rastgele seçilmiştir.
- Çoğaltma faktörü 3 ise NameNode, her blok için 3 adet DataNode IP’si sağlar. Örneğin:
- Blok A için = { DataNode 1, DataNode 4, DataNode 6 }
- Blok B için = { DataNode 3, DataNode 7, DataNode 9 }
- Her blok, tutarlı bir şekilde çoğaltma faktörünü korumak için 3 farklı DataNode’da kopyalanır.
- Tüm veri kopyalama işi 3 adımda gerçekleşir.
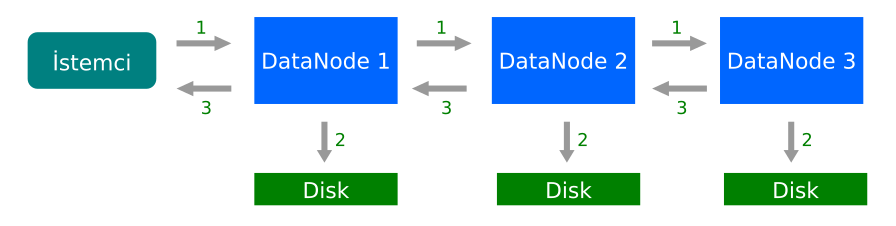
- Boru Hattı Kurma
- Veri Akışı ve Çoğaltma
- Boru Hattının Kapatılması
1. Boru Hattı Kurma
Blokları yazmadan önce, istemci, IP listelerinin her birinde bulunan DataNode’un verileri alamaya hazır olduğunu doğrulamaktadır. Bunu yaparken, istemci, ilgili bloğun ilgili listesindeki DataNode’ları bağlayarak blokların her biri için bir boru hattı oluşturur. Blok A’yı düşünelim.
Blok A için = { DataNode 1, DataNode 4, DataNode 6 }
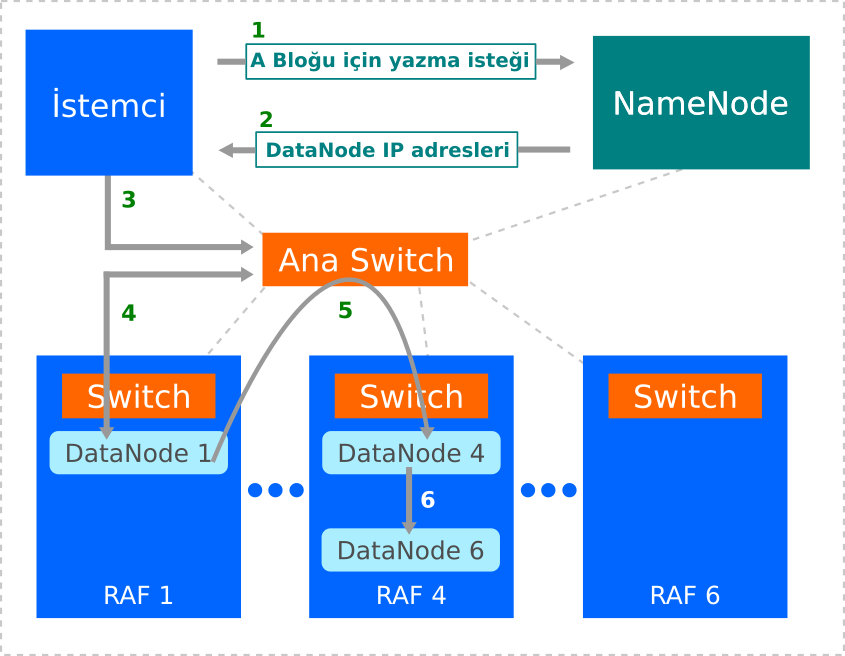 Boru hattı kurmak için aşağıdaki adımlar gerçekleştirilir:
Boru hattı kurmak için aşağıdaki adımlar gerçekleştirilir:
- İstemci listedeki ilk DataNode’u seçecek ve TCP / IP bağlantısı kuracaktır.
- İstemic DataNode 1’e bloğu almaya hazır olmasını bildirir. Ayrıca bloğun çoğaltılması beklenen DataNode 1’e diğer DataNode’ların (4 ve 6) IP adreslerinin verir.
- DataNode 1, DataNode 4’e bağlanır ve bloğu alması için hazır olmasını bildirir ve DataNode 6’nın IP adresini verir. Aynı işlem 6 için tekrarlanır.
- Daha sonra hazırlık işlemi terse doğru devam eder. Son olarak DataNode 1, istemciye tüm DataNode’ların hazır olduğunu ve DataNode’lar arasında boru hattı oluşacağını bildirir.
- Boru hattı kurulumu tamamlandı ve istemci veri akışına başlayacaktır.
2. Veri Akışı
Boru hattı hazırlandığında, istemci boru hattına seri halde veri iletir. İstemic sadece DataNode 1’e bloğu kopyalar. Çoğaltma işlemi daime DataNode’lar tarafından sırayla yapılır. Çoğaltma DataNode 1 -> DataNode 4 -> DataNode 6 şeklinde yapılır.
3. Boru Hattı Kapatılması
Blok 3 DataNode’da kopyalandıktan sonra, istemci ve NameNode verilerin başarıyla yazıldığından emin olmak için bir dizi onay alacaktır. Ardından, istemci TCP oturumunu sona erdirmek için boru hattını kapatacaktır. Onay işlemi ters sırada gerçekleşir. Son DataNode’dan ilk DataNode’a oradan istemciye son olarak da NameNode ulaşır. NameNode meta verilerini (MetaData) güncelleyecek ve istemci boru hattını kapatacaktır.
HDFS Okuma Mimarisi
Okuma işlemi için aşağıdaki adımlar gerçekleşir:
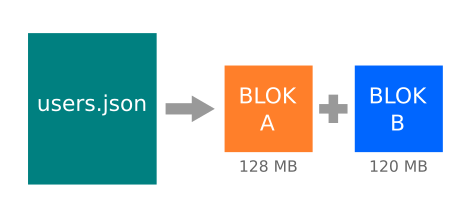
- İstemci “users.json” dosyası için blok meta verilerini NameNode’dan ister.
- NameNode her bloğun saklandığı DataNode listesini döndürür.
- İstemci blokların depolandığı DataNode’lara bağlanır.
- DataNode’lardan paralel olarak veri okumaya başlanır.
- İstemci tüm blokları aldığında, bunları birleştirir ve “users.json” dosyasını oluşturur.