on
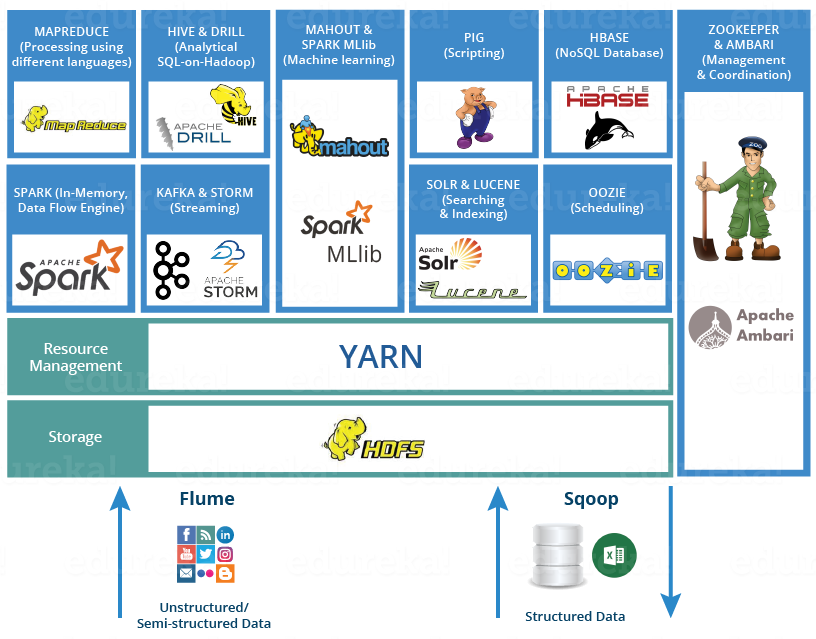
Hadoop Ekosistemi ve Kullanılan Araçlar
İçerik
- HDFS (Hadoop Distributed File System) Nedir?
- YARN (Yet Another Resource Negotiator) Nedir?
- MapReduce Nedir?
- Apache Ambari Nedir?
- Apache Chukwa Nedir?
- Apache HBase Nedir?
- Apache Hive Nedir?
- Hue Nedir?
- Apache Mahout Nedir?
- Apache Nutch Nedir?
- Apache Oozie Nedir?
- Apache Pig Nedir?
- Apache Solr Nedir?
- Apache Sqoop Nedir?
- Apache Storm Nedir?
HDFS (Hadoop Distributed File System) Nedir?
Hadoop’un depolama bileşenidir. HDFS, farklı büyük veri kümelerinin (yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış) depolanmasını mümküm kılar. Tüm veriyi tek bir birim olarak görmemizi (birden fazla sunucudaki veriye tek bir yerdeymiş gibi erişim) sağlar. HDFS yüksek verim alınabilecek şekilde optimize edilmiştir ve büyük dosyaları okurken ve yazarken en iyi sonucu alır. Ölçeklenebilirlik ve kullanılabilirlik HDFS’nin temel nitelikleridir. HDFS hem yazılım hem donanım arızasına karşı toleranslıdır. Başarısız olan düğümlerdeki veri bloklarını otomatik olarak tekrar kopyalar. İki temel bileşene sahiptir:
- NameNode
Ana düğümdür ve gerçek veri depolamaz. Meta verileri içerir, bir günlük dosyası veye içindekiler kısmı gibi düşünülebilir. Bu nedenle daha az depolama ve yüksek hesaplama kaynağı gerektirir. Verileri yazarken NameNode ile iletişim kurulur. - DataNode
Tüm veriler DataNode’larda saklanır. Daha fazla depolama alanına ihtiyaçları vardır.
YARN (Yet Another Resource Negotiator) Nedir?
YARN, Hadoop Ekosisteminin beyni olarak düşünülebilir. Kaynakları ve zamanlama görevlerini tahsis ederek tüm işleme faaliyetlerini gerçekleştirir. İki bileşene sahiptir:
- ResourceManager
İşlem taleplerini alır ve işlemin gerçekleşeceği yerlerde istekleri ilgili NodeManager’a aktarır. - NodeManager
Her DataNode’a kuruludur ve görevin yürütülmesinden sorumludur.
MapReduce Nedir?
Hadoop’un ana yürütme çerçevesi dağıtılmış ve paralel bir programlama modeli olan MapReduce’dür. MapReduce, büyük ölçekli, dağınık, hataya dayanıklı veri işleme uygulamalarının geliştirilmesini basitleştirmek için tasarlanmış olup, başta uygulama yazmak için bir yöntemdir. Geliştiriciler, hızlı veri erişimi için HDFS’de depolanan verileri kullanarak Hadoop için MapReduce işleri (jobs) yazarlar. MapReduce fikri, 2004 yılında iki Google mühendisinin “MapReduce: Büyük Kümeler Üzerinde Basitleştirilmiş Veri İşleme” (J. Dean, S.Ghemawat) başlıklı makalesinde ortaya çıkmıştır. Hadoop MapReduce, bu makalede açıklanan modelin açık kaynaklı bir uygulamasıdır.
Apache Ambari Nedir?
Apache Ambari projesi, Apache Hadoop kümelerinin hazırlanması, yönetimi ve izlenmesini sağlayarak Hadoop’un yönetimini basitleştirmeyi amaçlıyor. Ambari, RESTful API’leri ile desteklenen, sezgisel, kullanımı kolay bir Hadoop yönetimi web arayüzü sunmaktadır. Ambari sistem yöneticilerinin aşağıdakileri yapmasını sağlar:
- Bir Hadoop Kümesi Oluşturma
Ambari, herhangi bir sayıda ana bilgisayara Hadoop hizmetlerini yüklemek için adım adım bir sihirbaz sunar. Bu hizmetlerin konfigürasyonunu yünetir. - Hadoop Kümesini Yönetme
Ambari, Hadoop hizmetlerini tüm küme boyunca başlatma, durdurma ve yeniden yapılandırma için merkezi bir yönetim sunar. - Hadoop Kümesini İzleme
Ambari, Hadoop kümesinin sağlık durumunu izlemek için bir kontrol paneli sağlar. Ambari, metriklerin toplanması için Ambari Metrics System’den yararlanır. Ambari, sistem uyarıları için Ambari Alert Framework’ü kullanır ve önemli durumlar için (Örneğin bir düğümde sorun çıkması) sizi uyarır.
Apache Chukwa Nedir?
Apache Chukwa, büyük dağıtık sistemleri izlemek için açık kaynaklı bir veri toplama sistemidir. Apache Chukwa, Hadoop Dağıtık Dosya Sistemi (HDFS) ve MapReduce çerçevesinin üzerine inşa edilmiş ve Hadoop’un ölçeklenebilirliğinden ve sağlamlığından sorumludur. Toplanan verilerin en iyi şekilde kullanılmasını sağlamak için sonuçları görüntülemek, izlemek ve analiz etmek için esnek ve güçlü bir araç seti içerir.
Apache HBase Nedir?
HBase, Hadoop dosya sistemi üzerine kurulmuş ilişkisel olmayan, dağıtık bir sütun odaklı veritabanıdır. Açık kaynaklı bir projedir ve yatay olarak ölçeklenebilir. HBase, büyük miktarda yapılandırılmış veriye hızlı rastgele erişim sağlamak için tasarlanan Google’ın BigTable’ına benzer bir veri modelidir. Hadoop Dosya Sistemindeki verilere rasgele gerçek zamanlı okuma/yazma erişimi sağlar. Doğrudan veya HBase aracılığıyla veriler HDFS’ye kaydedilebilir.
Apache Hive Nedir?
Hive, yapılandırılmış verilerin Hadoop’ta işlenmesine yönelik bir veri ambarı alt yapısı aracıdır. Büyük verileri analiz etmek için Hadoop’un üstünde bulunur. Sorgulama ve analiz etmeyi kolaylaştırır. Hive, Facebook tarafından geliştirilmiş, daha sonra Apache tarafından açık kaynak bir proje olarak geliştirilmeye devam edilmiştir. Hive, SQL benzeri sorguları, çok büyük hacimli verilerin kolay yürütülmesi ve işlenmesi için MapReduce işlerini dönüştürür.
Hue Nedir?
Hue, verileri Apache Hadoop ile analiz etmek için kullanılan bir web arayüzüdür.
Apache Mahout Nedir?
Apache Mahout, öncelikle ölçeklenebilir makine öğrenme algoritmaları oluşturmak için kullanılan açık kaynak bir projedir. Apache Mahout, 2008 yılında Apache Lucene’nin bir alt projesi olarak başladı. 2010 yılında Mahout, Apache’nin üst düzey bir projesi haline geldi. HDFS’de bulunan verileri anlamlandırmak için makine öğrenmesinde kullanılan algoritmaları sağlar. Büyük verilerin, anlamlı bilgilere dönüştürülmesi için kullanılır.
Apache Nutch Nedir?
Nutch, web üzerinden bilgi toplamak içini kullanılan bir Web Crawler aracıdır. Web Crawler, web siteleri üzerinde gezinen araçlara denir. Google botları bunlara en iyi örnektir.
Apache Oozie Nedir?
Oozie, Apache Hadoop işlerini yöneten bir iş akışı zamanlayıcı sistemidir.
Apache Pig Nedir?
Apache Pig, MapReduce üzerindeki bir soyutlamadır. Apache Pig kullanarak Hadoop’daki tüm veri işleme işlemleri gerçekleştirilebilir. Veri işleme için Pig, Pig Latin adında bir dil sağlar. Bu dil, verileri okumak, yazmak ve işlemek için çeşitli operatörler sunar. Pig, yazılan komut dosyalarını girdi olarak kabul eden ve bu komut dosyalarını MapReduce işlerine dönüştüren Pig Engine adında bir bileşene sahiptir. Java’da karmaşık kodlar yazmak zorunda kalmadan MapReduce görevleri kolayca gerçekleştirilebilir. Pig Latin, SQL benzeri bir dildir.
Apache Solr Nedir?
Solr, arama uygulamaları geliştirmek için kullanılan açık kaynaklı bir arama platformudur. Lucene üzerine kurulmuştur. Solr ile yüksek performanslı, hızlı ve ölçeklenebilir uygulamalar geliştirilebilir. CNET Networks şirketinin web sitesine arama yetenekleri eklemek için 2004 yılında Solr’u geliştiren Yonik Selly’dir. Ocak 2006’da Apache tarafından açık kaynak pir proje haline getirildi. Solr kullanarak Lucene’nin bütün özelliklerinden faydalanılabilir. Bazı özellikler:
- RESTfull API
Solr ile iletişim kurmak için Java bilmeye gerek yoktur. Girdi olarak XML, JSON, CSV gibi dosya biçiminde belgeler verip aynı biçimde çıktılar alınır. - Tam Metin Arama
Solr, belirteçler, cümleler, yazım denetimi, joker karakter ve otomatik tamamlama gibi tam metin aramsı için gereken tüm özellikleri sağlar. - Yönetici Arayüzü
Solr, günlükleri yönetmek, belgeleri eklemek, silmek, güncellemek, aramak gibi olası görevleri yerine getirmek için kullanabildiğimiz bir kullanıcı arayüzü sunar.
Apache Sqoop Nedir?
Sqoop, toplu verilerin Apache Hadoop ve ilişkisel veritabanları gibi yapılandırılmış veri depoları arasında verimli bir şekilde aktarılması için tasarlanmış bir araçtır.
Apache Storm Nedir?
Apache Storm, ücretsiz ve açık kaynak dağıtılmış gerçek zamanlı hesaplama sistemidir. Storm, Hadoop’un toplu işlem için yaptıklarını gerçek zamanlı olarak işleme için sınırsız veri akışlarını güvenilir şekilde işlemek için kolaylık sağlar. Kullanımı karmaşık değildir. Storm ayrıca ilk seferde başarılı bir şekilde işlenmemiş verileri yeniden yürütme özelliğiyle birlikte verilerin garantili işlenmesini sağlayabilir.